- Bitmaker blog
- Posts
- Beyond Web Scraping: The Art of Finding APIs on Websites
Beyond Web Scraping: The Art of Finding APIs on Websites
Mastering APIs for Web Scraping Success
Hugo Luque & Erick Gutierrez
October 05, 2023
The world of Web Scraping is fascinating and offers endless possibilities for collecting data from the vast Internet. However, before diving into complex techniques like using Selenium or Scrapy, it's crucial to understand the existence of APIs, which can be a goldmine of structured and easily accessible data. In this article, Bitmaker will help you to find APIs in web pages and give you some recommendations on how to do it.
What is an API?
An API, or Application Programming Interface, is a set of protocols and tools that enables different software to communicate with each other. Imagine an API like a waiter in a restaurant: you make your choice (request) from the menu, the waiter takes your order to the kitchen (system), and then returns with your food (response). In the context of the web, APIs allow applications to request information from a server and receive a response.

Why Search for APIs?
Turning to APIs offers significant advantages over traditional web scraping, and here are some key reasons:
Consistency and Structure: Unlike web content that frequently changes, APIs provide data in structured manner and maintain consistency in their presentation, reducing long-term code maintenance.
Access Efficiency: APIs allow direct access to the desired data, avoiding the unnecessary loading of an entire web page. This saves time and resources.
Real-Time Updates: Many APIs offer real-time data, providing a more up-to-date view than static scraping.
Fewer Legal Issues: Some websites prohibit scraping in their terms of service. However, if they offer an API, it implies consent to access that data as long as the established rules are followed."a
How to Find APIs on a Web Page
Identifying APIs requires a methodical approach and a bit of research:
Browser Tools: By using the browser's developer tools and navigating to the 'Network' tab, you can monitor the network requests a web page makes when it loads. Requests labeled as XHR are often indicative of API calls.
Source Code Inspection: Some websites may have links to their API endpoints embedded directly in their source code. By inspecting and searching for API-related terms like "endpoint," "RESTful," or ".json," you may stumble upon clues.
Documentation: Larger sites that offer public access to their data via APIs often have a documentation section. This is a goldmine for understanding how to access and use this data.
Challenges When Using APIs in Web Scraping
While APIs can be an invaluable source of structured data, they also present their own set of challenges. Below, we explore some of the common issues you might encounter when interacting with APIs and how to address them:
Authentication Issues:
Challenge: Not all APIs are freely accessible. Many require specific authentication to ensure that only authorized users access the data.
Solution: As you mentioned, it's often necessary to provide authentication headers, tokens, or cookies to access the API. Be sure to review the API documentation to understand its specific authentication requirements. In many cases, you'll need to register first to obtain an API key that you should include in your requests.
Usage Limits:
Challenge: Many APIs set limits to prevent abuse. These limits may be related to the number of requests per minute/hour, the amount of data you can retrieve, or the total number of calls in a specific period.
Solution: Again, it's essential to review the documentation to understand the specific limits. If you're approaching these limits, consider implementing delays in your requests or spreading your calls over time. If you're working on a larger project, you might also consider looking for a premium or paid version of the API that offers more generous limits.
Identification as a DDoS Attack:
Challenge: If you make requests to an API too quickly or in large volumes over a short period, the server may interpret it as a DDoS attack.
Solution: Implement controls to ensure that your requests aren't too frequent. Use tools or libraries that allow you to set delays between requests. Additionally, consider using proxies to distribute your requests, but always within ethical and legal guidelines.
Changes in Data Structure:
Challenge: While APIs are typically more consistent than web pages, they can still change over time, especially if the API is updated to a new version.
Solution: Stay alert to announcements from the API provider regarding possible updates or changes. It's good practice to implement checks in your code to detect unexpected changes in the data structure and alert you to potential issues.
By addressing these challenges and solutions, you're better positioned to make the most of APIs in your web scraping projects, ensuring a steady and reliable flow of data.
Guided Example: Scraping the Premier League Page
Objective: Extract data about Premier League matches, teams, or players using its internal API.
Identify the Target Page
For this example, the Premier League website will be our target. It is a data-rich site, and due to the amount of information it presents, it likely uses an API to load content dynamically. https://www.premierleague.com/stats/top/players/goals

Note: Prepared by the authors
Open the Browser's Development Tools
Regardless of the browser you're using (Chrome, Firefox, Edge, etc.), they all have built-in development tools. Open the Premier League page and then open the development tools (usually you can do this with the F12 key or by right-clicking on the page and selecting "Inspect" or "Developer Tools").

Note: Prepared by the authors
Clear the 'Network' Panel History
Within the development tools, go to the 'Network' tab. This is where all the page's requests are logged (images, scripts, stylesheets, and most importantly for us, API calls). Before proceeding, make sure to clear the current history so that future requests are easier to identify. Typically, there is a "clear" button or a small trash icon you can click.

Note: Prepared by the authors
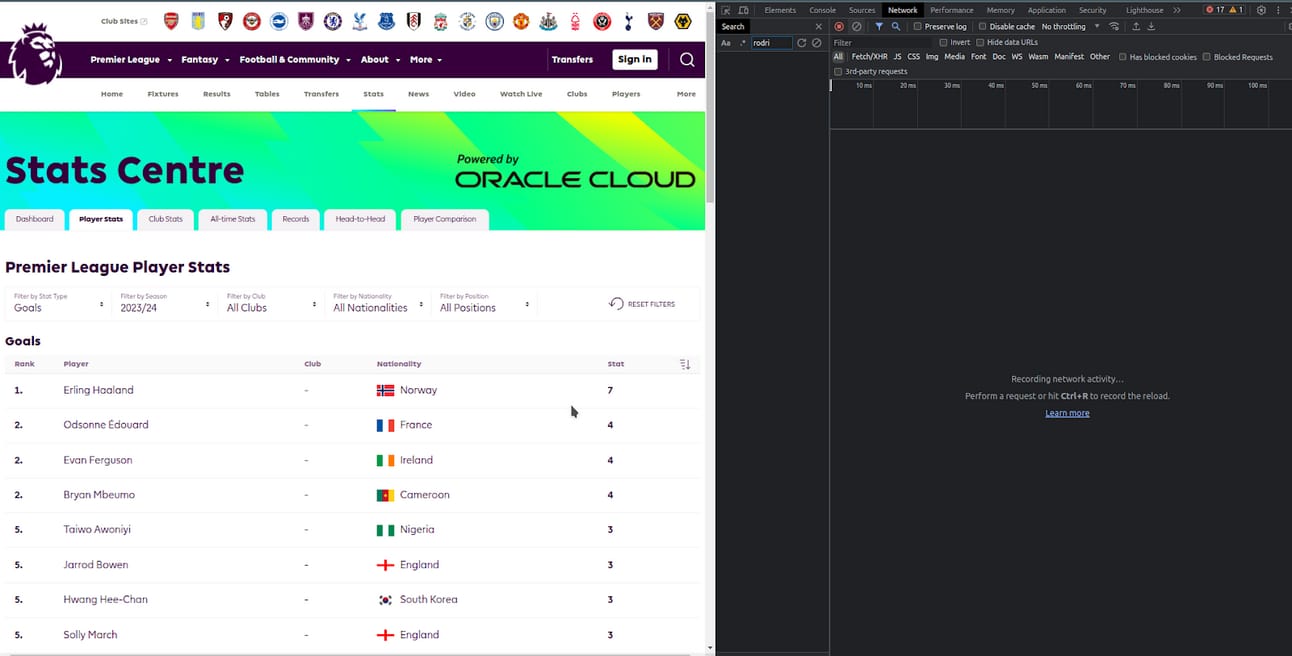
Note: Prepared by the authors
Navigate to Dynamic Content
On the Premier League website, navigate through pagination or find a section that loads content dynamically. Watch in the 'Network' tab how various requests are logged as you interact with the page.

Note: Prepared by the authors
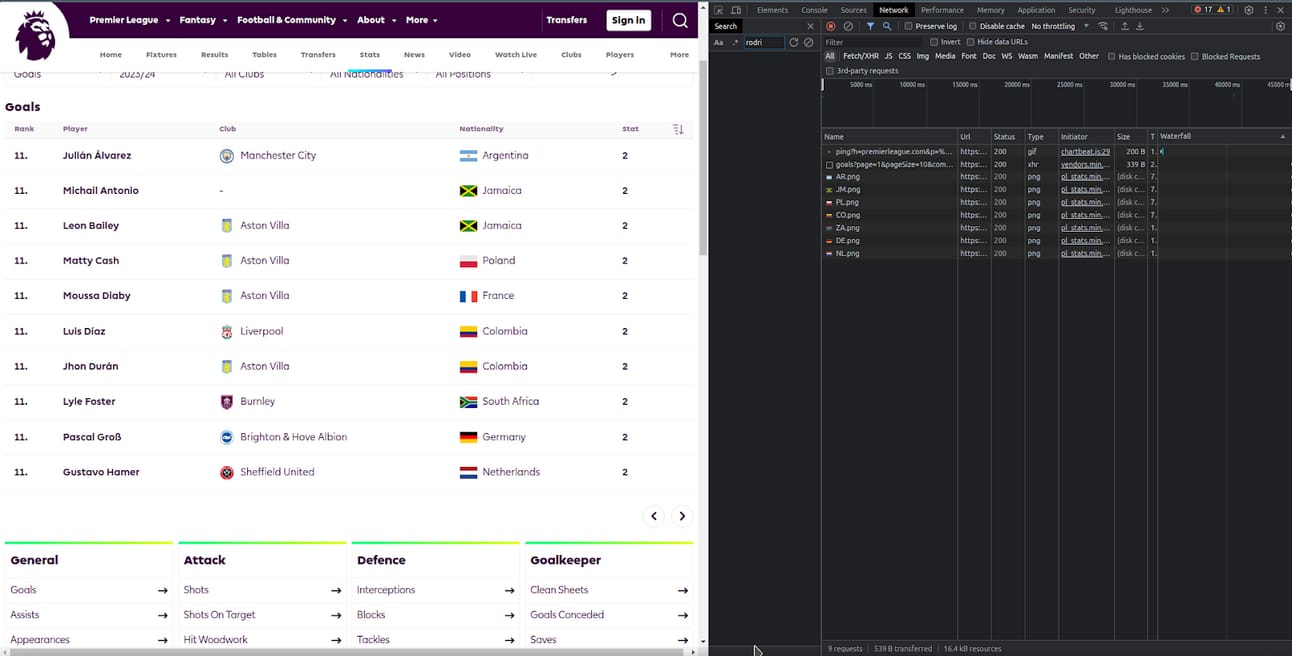
Note: Prepared by the authors
Identify the API Call
Among all the requests, look for those that seem like API calls. These usually have a 'GET' method, and in the 'Type' column, you will likely see 'xhr' or 'fetch.' If you click on these requests, you can see the details. Look for the one that contains the information you need (e.g., match details or player statistics).

Note: Prepared by the authors

Note: Prepared by the authors
Extract and Use the API Query
Once you've identified the correct request, you can right-click on it and copy the request's URL. With this URL, you can replicate the request in your code using tools like Python's requests to obtain the same data. Also, be sure to review the request's headers in case you need additional information, such as authentication tokens, to make your own request.

Note: Prepared by the authors

Note: Prepared by the authors
Tools for Interacting with APIs
Once you've found an API, you need the right tools to interact with it:
Scrapy: While known for being a web scraping tool, Scrapy can also be used to interact with APIs. It can handle authentication, custom headers, and sessions.
import scrapy
class ApiSpider(scrapy.Spider):
name = 'api_spider'
start_urls = ['https://api.example.com/data']
def parse(self, response):
jsonresponse = response.json()
Requests: This is a Python library that makes sending HTTP requests easy. It's great for interacting with RESTful APIs, where you can make GET calls to retrieve data or POST to send data.
import requests
params = {'key1': 'value1', 'key2': 'value2'}
headers = {'Authorization': 'Bearer YOUR_API_TOKEN'}
response = requests.get('https://api.example.com/data', params=params, headers=headers)
if response.status_code == 200:
data = response.json()
print(data)
else:
print(f"Error: {response.status_code}")
Postman: It's a development tool that simplifies testing and exploring APIs. It allows you to set up requests, authenticate, and view responses in an easy-to-read format.
https://learning.postman.com/docs/getting-started/first-steps/sending-the-first-request/Postman is a tool that simplifies testing and exploring APIs. To make a request:
Open Postman.
Select the request type (GET, POST, etc.).
Enter the API URL.
If the API requires headers, parameters, or other data, enter them in the respective sections.
Click 'Send' and observe the response.
When interacting with APIs, it's essential to use tools specifically designed for that task. While scraping tools like Scrapy, Beautiful Soup 4, and Selenium are powerful and valuable for extracting data from websites, using them for simple API queries can result in an overly complicated and less efficient approach.
Python's requests library, on the other hand, is designed specifically for making HTTP requests in a simple and straightforward manner. With clear and concise syntax, requests allow you to make API calls, handle responses, send data, manage headers, and authentication, all with minimal effort. Additionally, by using requests, you reduce computational overhead and execution time compared to scraping tools that require more processing
Conclusion
While web scraping can be a powerful method for collecting data, do not underestimate the power and efficiency of APIs. By adopting a balanced approach and leveraging all the tools at your disposal, you can maximize the quality and quantity of data you collect.
If you are interested in developing projects or have an idea in mind, Contact us today to schedule a meeting and get started together on this path.
At Bitmaker we are committed to sharing our knowledge and reporting on the critical issues involved in Web Scraping, we invite you to read this technical article: Mastering Selectors: Your Essential Guide to Navigate the DOM